淺析藍牙模塊在車聯(lián)網(wǎng)、可穿戴設(shè)備及物聯(lián)網(wǎng)領(lǐng)域的應(yīng)用與技術(shù)賦能

隨著無線通信技術(shù)的飛速發(fā)展與物聯(lián)網(wǎng)(IoT)概念的深度滲透,藍牙技術(shù)憑借其低功耗、低成本、高可靠性和便捷的組網(wǎng)能力,已成為連接物理世界與數(shù)字世界的關(guān)鍵橋梁之一。藍牙模塊作為該技術(shù)的硬件載體,其應(yīng)用已從傳統(tǒng)的音頻傳輸,廣泛延伸至車聯(lián)網(wǎng)、可穿戴設(shè)備及廣闊的物聯(lián)網(wǎng)領(lǐng)域,并持續(xù)推動著相關(guān)技術(shù)服務(wù)模式的創(chuàng)新與升級。
一、藍牙模塊在車聯(lián)網(wǎng)領(lǐng)域的應(yīng)用
在車聯(lián)網(wǎng)(V2X)生態(tài)中,藍牙模塊扮演著“智能鑰匙”與“數(shù)據(jù)輕軌”的雙重角色。
- 無鑰匙進入與啟動系統(tǒng)(PEPS):低功耗藍牙(BLE)模塊實現(xiàn)了智能手機與車輛的安全配對,允許用戶通過手機APP完成車門解鎖、啟動引擎、預(yù)先調(diào)節(jié)空調(diào)等操作,極大提升了用車便利性與科技感。
- 車載信息娛樂系統(tǒng):藍牙經(jīng)典音頻模塊實現(xiàn)了手機與車機的無線連接,用于免提通話、音樂流媒體播放,是提升駕駛安全與娛樂體驗的基礎(chǔ)配置。
- 車內(nèi)外數(shù)據(jù)采集與傳輸:BLE模塊連接車載診斷系統(tǒng)(OBD)、胎壓監(jiān)測傳感器(TPMS)等,將車輛狀態(tài)數(shù)據(jù)實時傳輸至駕駛員手機或云端平臺,為預(yù)防性維護、駕駛行為分析提供數(shù)據(jù)支撐。
- 智慧停車場與車輛服務(wù):車輛通過藍牙模塊可與停車場閘機、充電樁、洗車機等設(shè)施進行短距離通信,實現(xiàn)自動扣費、引導(dǎo)泊車、智能充電等無縫服務(wù)體驗。
二、藍牙模塊在可穿戴設(shè)備領(lǐng)域的應(yīng)用
可穿戴設(shè)備是藍牙技術(shù),特別是BLE技術(shù)應(yīng)用最成熟、最普及的領(lǐng)域之一。
- 健康與運動監(jiān)測:智能手表、手環(huán)、智能衣物等內(nèi)置藍牙模塊,持續(xù)采集用戶的心率、血氧、睡眠、運動軌跡等生理與活動數(shù)據(jù),并同步至手機APP或云端,為用戶提供健康洞察與運動指導(dǎo)。
- 設(shè)備控制與信息中繼:藍牙耳機、智能眼鏡等設(shè)備通過藍牙模塊連接手機,實現(xiàn)音頻傳輸、語音助手喚醒、信息通知預(yù)覽等功能,成為個人數(shù)字生活的延伸。
- 社交與支付功能:設(shè)備間通過藍牙實現(xiàn)快速配對與數(shù)據(jù)交換(如交換聯(lián)系方式),并支持模擬門禁卡、公交卡及移動支付,拓展了可穿戴設(shè)備的實用邊界。
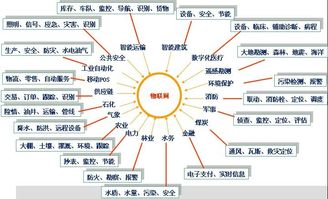
三、藍牙模塊在物聯(lián)網(wǎng)(IoT)領(lǐng)域的廣泛應(yīng)用
物聯(lián)網(wǎng)的核心是“萬物互聯(lián)”,藍牙模塊因其特性,在眾多場景中成為理想的連接解決方案。
- 智能家居:藍牙Mesh網(wǎng)絡(luò)技術(shù)支持大量設(shè)備(如燈泡、開關(guān)、傳感器、窗簾電機)組成自修復(fù)網(wǎng)絡(luò),實現(xiàn)全屋智能照明、環(huán)境自動化控制,無需依賴中心網(wǎng)關(guān)即可穩(wěn)定運行。
- 資產(chǎn)追蹤與室內(nèi)定位:基于BLE的信標(biāo)(Beacon)技術(shù),在倉庫、工廠、商場、醫(yī)院等場所,可實現(xiàn)貨物、工具、醫(yī)療設(shè)備的高精度室內(nèi)定位與軌跡追蹤,以及向顧客推送基于位置的個性化信息。
- 工業(yè)物聯(lián)網(wǎng)(IIoT):在工廠自動化中,藍牙模塊用于連接傳感器、執(zhí)行器和手持終端,實現(xiàn)設(shè)備狀態(tài)監(jiān)控、參數(shù)配置、數(shù)據(jù)采集與無線控制,降低布線成本與復(fù)雜度。
- 智慧醫(yī)療:藍牙連接血糖儀、血壓計、體溫貼等醫(yī)療設(shè)備,將測量數(shù)據(jù)自動上傳至手機或醫(yī)院信息系統(tǒng),便于患者自我管理與醫(yī)生遠程監(jiān)護。
四、藍牙技術(shù)對物聯(lián)網(wǎng)服務(wù)模式的賦能
藍牙模塊的普及不僅在于連接設(shè)備,更深層次地驅(qū)動了物聯(lián)網(wǎng)技術(shù)服務(wù)的演進:
- 數(shù)據(jù)服務(wù)精細化:藍牙實現(xiàn)了海量終端數(shù)據(jù)的便捷采集,使得服務(wù)商能夠基于更精確、實時的數(shù)據(jù),提供個性化健康管理、預(yù)測性設(shè)備維護、精準營銷等增值服務(wù)。
- 交互體驗無感化:低功耗與快速連接特性,使得設(shè)備間的交互(如自動簽到、無感支付)趨于“無感”,提升了用戶體驗的流暢度與自然度。
- 系統(tǒng)部署靈活化:藍牙,特別是Mesh技術(shù),降低了大規(guī)模傳感器網(wǎng)絡(luò)部署的難度與成本,使智慧樓宇、城市傳感網(wǎng)絡(luò)等項目的實施更加靈活高效。
- 生態(tài)構(gòu)建標(biāo)準化:藍牙技術(shù)聯(lián)盟(SIG)推動的標(biāo)準統(tǒng)一,確保了不同廠商設(shè)備間的互操作性,加速了跨品牌、跨品類物聯(lián)網(wǎng)生態(tài)系統(tǒng)的形成與繁榮。
###
藍牙模塊已深度融入車聯(lián)網(wǎng)、可穿戴設(shè)備及物聯(lián)網(wǎng)的各個層面,從實現(xiàn)基礎(chǔ)無線連接,到支撐復(fù)雜的網(wǎng)狀網(wǎng)絡(luò)與智能化服務(wù)。隨著藍牙技術(shù)不斷演進(如LE Audio,更高精度定位),其在抗干擾能力、音頻質(zhì)量、定位精度和網(wǎng)絡(luò)規(guī)模上將持續(xù)突破。藍牙模塊將繼續(xù)作為物聯(lián)網(wǎng)基礎(chǔ)設(shè)施的重要組成部分,與5G、Wi-Fi、UWB等技術(shù)互補融合,共同推動一個更智能、更互聯(lián)、更便捷的數(shù)字世界加速到來。
如若轉(zhuǎn)載,請注明出處:http://www.videocoop.cn/product/13.html
更新時間:2026-06-19 11:35:26